

Introduction
Olaf Ronneberger created U-NET for BioMedical Image Segmentation in 2015; it is an end-to-end fully convolutional network (FCN). (Paper link)
U-NET contains convolutional layers because of which it can accept images of any size, and it focuses on image classification, where input is an image and output is one label.
Computer Vision
Computer Vision focuses on the problem of helping computers to “see” “and understand the content of digital images such as photographs and videos.
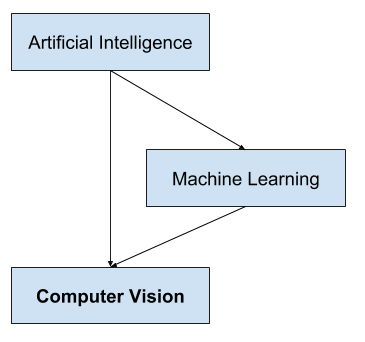
Computer Vision is different from Image Processing. Image processing typically creates a new image from an existing image by simplifying or enhancing the content in some way. It is called digital signal processing and is not concerned about the understanding of image content. A given computer vision system may require image processing to be applied to raw input, e.g., pre-processing images.
Examples:
- Cropping the bounds of the image, such as centering an object in a photograph.
- Normalizing photometric properties of the image, such as brightness or color.
- Removing digital noise from an image, such as digital artifacts from low light levels.
Deep Learning has changed the Computer Vision field rapidly in the last few years. Here we will discuss one specific task in Computer Vision called Semantic Segmentation and a particular architecture , namely U-NET.
Computer Vision Applications:
Object Detection
Object Detection deals with detecting instances of semantic objects of a certain class (such as humans, buildings, or cars) in digital images and videos. It extends localization where the image is not constrained to have only one object but can contain multiple objects. ’It’s task is to classify and localize all the objects in the image.
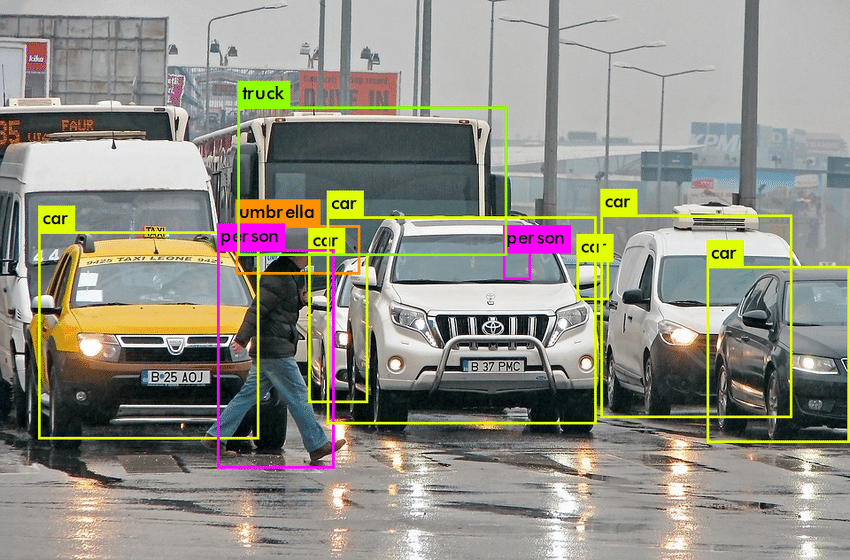
Instance Segmentation
Instance Segmentation detects instances, gives categories, and label pixels. It includes the identification of the objects at a detailed pixel level. It combines object detection and localizes them using a bounding box.

Semantic Segmentation
Semantic Segmentation is a pixel-based classification; it classifies each pixel of an image as belonging to a particular class. It can be used for land cover classification or for identifying roads or buildings from satellite imagery.
Object Detection Semantic Segmentation Instance Segmentation

We will specifically focus on the Semantic Segmentation below using a Fully Convolutional Network called U-NET.
U-NET
U-NET is built as an encoder network followed by a decoder network. In classification, where the end result focuses on the deep network, semantic segmentation requires not only discrimination at pixel level but also a mechanism to project the discriminative features learned at different stages of the encoder onto the pixel space.
- The encoder contains covenant layers followed by pooling operation. It is used to extract factors in the image.
- The decoder uses transposed convolution to permit localization, and it is a fully connected network of layers.
U-NET Architecture
U-NET architecture looks like the letter” ”U’ which derives its name.
Figure 6. U-NET Architecture (example for 32×32 pixels in the lowest resolution). Each blue box corresponds to a multi-channel feature map. The number of channels is denoted on top of the box. The x-y-size is provided at the lower-left edge of the box. White boxes represent copied feature maps. The arrows denote the different operations
This architecture consists of three sections:
- Contraction – Each block takes an input applied to two 3×3 convolution layers, followed by a 2×2 max pooling. The number of feature maps gets doubled at each pooling layer.
Figure 6. Contracting Path
- Bottleneck – The bottleneck layer uses two 3X3 convolution layers and a 2X2 up convolution layer. It mediates between the contraction layer and the expansion layer.
Figure 7. Bottleneck Path
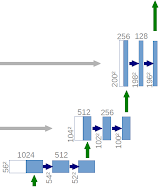
- Expansion section – The expansion Section is the heart of this architecture ; it consists of several expansion blocks with each block passing the input to two 3×3 Conv layers and a 2×2 upsampling layer that halves the number of feature channels
Deep Learning Applications in Healthcare:
- Medical Imaging: Medical imaging techniques such as MRI scans, CT scans, ECG, are used to diagnose dreadful diseases such as heart disease, cancer, brain tumor. Hence, deep learning helps doctors analyze diseases better and provide patients with appropriate treatment.
- BioMedical Image Diagnosis: Now machines do augment analysis performed by radiologists, it reduces the time required to run diagnostic tests
- Alzheimer’s disease: Alzheimer’s is one of the most significant challenges that the medical industry faces. Deep learning techniques are used to detect ” Alzheimer’s disease at an early stage.
Pros of U-NET
- It can be used for any reasonable image masking task
- High accuracy is given proper training, adequate dataset, and training time
- This architecture is input image size agnostic since it does not contain fully connected layers
Cons of U-NET
- It takes a significant amount of time since it has so many layers.
- Requires relatively high GPU memory footprint for larger images
Conclusion
U-NET architecture can be used for image localization, which helps in predicting the image pixel by pixel. It also achieves good performance on very different biomedical segmentation applications. The author of U-net claims in his paper that the network is strong enough to make good predictions based on even fewer data sets by using excessive data augmentation techniques.


