


Introduction
Many businesses deploy advanced data analysis and Business Intelligence to improve their performance. These analytical processes involve handling data from different data sources. However, there may be multiple naming conventions that could create a conflict when integrating the datasets. This results in duplications and errors, causing inconsistent reporting and inaccurate business results.
Consider a region column in a social media dataset. Here, one of the values is represented as ‘NA’, but ideally, it should have been represented as ‘North America’. On the other hand, a similar dataset has a value of “United States” in place of “North America”. As a result, the above record will not be tagged to the region column while integrating these datasets.
Most of the mismatches while connecting the data arise in the Business Name (account name/ customer name) fields due to different notations. These may be present in sales, marketing, transactional, and social media data.
- Internal sources of data – Sales, Marketing, transactional data, and other forms of in-house data
- External sources of data – Social media data and data from other vendors

Hence, when we try to integrate all these data sources, it might result in many duplications because of incorrect naming conventions or multiple naming conventions. As a result, this may not accurately represent the company’s business analysis and the subsequent recommendation arising out of these data.
The impact of multiple naming conventions include:
- Duplicated records
- Inaccurate Insights
- Untagged accounts
- Lack of integrity
Hence, the best solution would be to consolidate similar data automatically through advanced text analytics algorithms.
Solution for Integration
A practical solution to address the above issues includes using advanced text analytics with popular algorithms such as FUZZY LOGIC.
Fuzzy Logic is a type of Natural Language Processing (NLP) that helps identify and group similar business records. It tries to associate similar business records that were misrepresented or misspelled. Hence, we will obtain a cleansed dataset.
Fuzzy Logic is widely used in numerous fields, including control systems engineering and optimization.
Standardizing account names using Fuzzy Logic
In the example below, we are trying to integrate three different data sets from three different sources with business account names in multiple formats. However, we can connect all the three account names into one record using the Fuzzy Logic algorithm.
| Data source 1 | Data source 2 | Data source 3 |
| CITIBANK | CITIBANK INC | CITIBANK PVT |
As a result, the algorithm will group all versions of Citibank and assign them to a standardized notation of CITIBANK LTD.
Key Advantages of Fuzzy Logic
- One Single Source of Truth
- Accurate insight and summary of the data
- Eliminates duplicates
- Automated process of identifying similarly sounding business names
- Alternative text mining process as against manual clean-up’s which usually results in human error (Automation)
How does Fuzzy Logic work?
The text analytics algorithm identifies the pairs of words for every combination of account names from multiple sources. The algorithm looks for similarly sounding words based on various parameters and identifies those accounts from multiple sources to cluster together and form a single name.
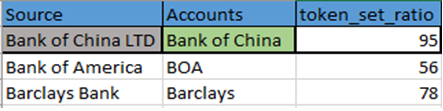
It then runs through the algorithm to generate the token sort ratio. This ratio indicates the distance between the pair of words and assigns a percentage value. The fuzzy logic token sort ratio helps accurately identify the exact word distance between two values.
Token_sort_ratio:
75-100% – Exact/approximate match
60-75% – Moderate match
40-60% – Slight match
Let’s assume that there are company names from three different data sources (three excel lists). The algorithm will take one list as the source, i.e., the primary list, and cross-check with every single account name on the other lists. The threshold limits will identify two account matches, i.e., the algorithm will predict the distance between the words, which would help us identify the match for the account that is present in the primary list.
Conclusion:
Normalization of datasets using fuzzy logic algorithms can solve multiple real-world problems businesses face in data cleansing. Also, this process eliminates inconsistency in matching pairs of words. Furthermore, fuzzy algorithm automation saves a considerable amount of time required while integrating/normalizing the dataset.


