


When it comes to designing the data framework within the organization, a serverless computing application stack is all the rage now. Gone are the days where we wait for pristine servers to be provisioned to serve a request. Organizations in their pursuit to ensure analytics driven processes and decision-making, are re-engineering their infrastructure to suit the needs of contemporary analytics workloads. In a 2016 study, ‘Voice of the Enterprise (VotE): Cloud Transformation, Workloads and Key Projects 2016’, by 451 Research, it was found that 37% of IT decision-makers were already using the architecture of serverless computing to some degree. Fourteen percent of decision-makers were serverless in production and 11% were testing the technology. Twelve percent of the respondents were in initial discovery phases.
The buzzword ‘pay for what you use’ has led to serverless architecture turning mainstream. To organizations evaluating whether to go serverless, this blog will discuss the pros and cons of serverless architecture with a reference implementation detail.
Serverless framework – reality or hype?
‘Serverless framework’, in layperson’s terms, means that your backend computation logic will run on vendor-maintained infrastructure where you can run your own code and for which you will be charged only for your usage. The onus of keeping the infrastructure up and running at all times falls on the vendor.
There are many potential benefits to serverless computing, including reduced costs and speedy deployments for certain businesses. However, there are few concerns such as vendor lock-in that might be an issue when it comes to migration for businesses.
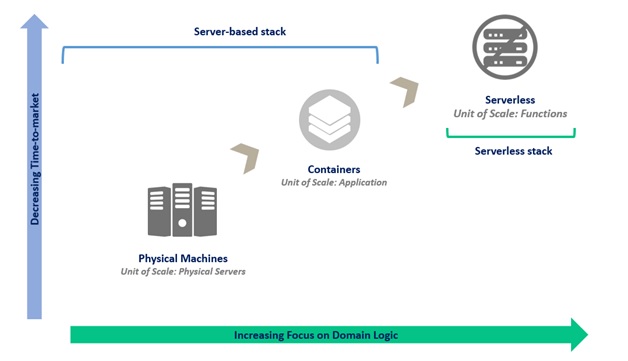
Data-as-a-service paves way for a well interconnected data landscape where different applications communicate and converse over APIs (Application Programming Interface). The demand and scale are never predictable and never consistent. There is no regard for the past and future states. This sets the stage for hopping off the comfort zones of server-bound processing to a dynamic and infinite serverless paradigm.
Why companies need to go serverless
A clinical ask when it comes to all our customers is to design an ad-hoc query enabled, cost-cutting cloud-based, configuration driven data harmonization, and advanced analytics enabled framework. Impressive cut in costs to provision, maintaining servers, high availability, and pay-per-use (FaaS – function-as-a-service) strategies play heavily in favor of going in the direction of serverless computing.
Also, server-bound applications result in a slow start in development as provisioning even rudimentary development set-up demands a tedious infrastructure with complex application stacks. It also puts forth a lot of operational challenges such as running costs, scalability, security, server maintenance, all of which isn’t independent of a hand-operated intervention. If serverless computing can alleviate all these problems, wouldn’t that be a wiser business decision?
Evaluating the serverless space
In order to implement an interactive ad-hoc analysis platform, there are two critical challenges:
- Establishing central ground truth, computation of metrics, validation and periodic refresh
- API, request parser and appropriate backend infrastructure for dynamic querying from different applications and users
The first challenge lies purely in the data domain that requires data architectures to be designed and scaled. The second challenge of setting up and running the service is of current interest to us. As we design a solution to deliver data-as-a-service, we need to take the following constraints into consideration:
- Request volume
- Request rate
- Request to response SLA
- Input and output definitions
- Usage and thresholds
- Monitoring and alerting
- Fault tolerance
Use case: Implementing a serverless interactive analytics platform
When we evaluated our client’s on premise set up, the time and cost to set up and manage the entire stack for data service was not only cost ineffective, but also a tedious and labor-intensive process. We analyzed various options, total costs of ownership, time-to-deliver, and accountability and finally zeroed in on the Amazon Web Services (AWS) serverless offering. AWS is an industry leader in this space and provides us the much-needed components such as AWS Lambda, AWS S3, AWS Cognito, API Gateway, Simple Queuing Service, DynamoDB and Redshift to set up a serverless interactive querying stack.
Architecting server bound applications demands a firm grip and dexterity in understanding the underlying key concepts of HTTP (HyperText Transfer Protocol) based protocols and API services.
We evaluated several MPP stores using our custom load testing module to zero in on Redshift as our preferred set up to support the client’s request which had stringent SLAs. We were tasked with building resilient data architecture to accommodate hundreds of concurrent users every minute and maintain a 60:40 ratio of simple to complex queries.
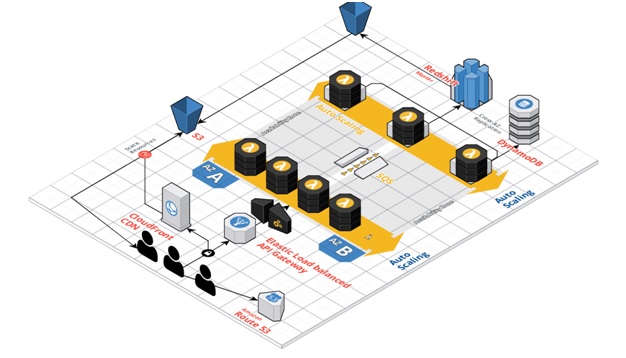
The client’s query request crisped as a JSON (JavaScript Object Notation) is sent over a secure HTTP to the AWS Lambda with Authentication (AWS Cognito) and HTTP hand out (AWS API Gateway) taken care of with almost no hassle. An eloquent ANSI SQL compliant query is constructed based on the request JSON and is ready to hit database. The query is submitted to a high available FIFO (first-in-first-out) queue, with the SQS (simple queuing service) decoupling from the existing HTTP connection with the client. Intelligent consumer of the query message from SQS, waits for the right time to hit Redshift. The right time is defined by the availability of Redshift and IPs in the VPC (virtual private cloud). The dispatched queries are executed in a Redshift cluster and the results are used by the client from S3.
There are some key limitations enforced by AWS Lambda. They are:
- Number of IPs available in VPCs define the number of concurrent requests
- Timeout configuration in Lambda
- Memory limitations for the output data to be siphoned
In our client scenario, we were able to implement 95% of all their requests even with the constraints listed above. For the remaining scenarios, where the users were expecting long run times or massive data download, we nudged for business justification and built alternate solutions that suited the limited scale and frequency of use.
Serverless Application model: Instantly Scalable and Stateless
A fully-functional, focused agile application development on top of a serverless application model reduces the time spent on infrastructure administration and decreases time-to-market. It scales big with nearly zero effort involved in operational thinking for scalability.
Another advantage towards this is that it is stateless. Maintaining application states had been a huge burden on server bound stacks, where going serverless inherently makes your application stateless. All your web tokens, user actions, and process states are primarily maintained in your own databases.
Downside of serverless data
Ferrying big data in a serverless application model can also have a few cons to your application. A tight tie-up with the service provider can act as a hiccup to going serverless. We become more dependent on tools and services that the third-party platforms offer. This blows out all the possible open source support you can find in case of a server-bound model.
One of the few complications we hit while going serverless is insufficient timeouts of several services. The AWS API Gateway times out if there is a connection lag of more than 29 seconds! The anonymous computing power AWS Lambda can be active only for five minutes. One cannot use AWS Lambda for synchronous operations that exceed this time limit. Timed out Lambda’s state is unknown as well. In other words, we cannot resume from where we last left. We might even hit cold starts while provisioning Lambda for the first time and it should be only thought of as a Black Box. The functionality to cross-examine such platforms is still a work in progress and any production grade rollout must be done carefully to avoid any developing operations debacle.
One needs to proactively plan for continuous integration, testing and deployment strategies for a serverless environment before it becomes an intractable code play area for the masses.
To go serverless or not?
The question lingers whether to go serverless or not. Of the numerous advantages that serverless models bring over server bound application models, let’s not forget the constraints of the latter. However, the writing on the wall is clear. The future is going to be a serverless one and it is just a matter of resolving the limitations. Going serverless even in the current scenario can result in huge benefits if the potential limitations are thoroughly understood and workarounds are designed to overcome them.
Accelerate your Data Engineering capabilities
At LatentView Analytics, we follow a business-focused approach to data engineering to align analytics and technology. Our workload-centric architectures are designed to meet different needs of business stakeholders. To help unleash all levels of data analytics capabilities and turn it into a competitive advantage for your business, please get in touch with us at: marketing@latentview.com


