


Decoding the Data Science Terrain: Part 1
Data and analytics is a vast and complex area, and it makes sense to start with a map of the terrain. My colleague, Karthikeyan Sankaran, has created a comprehensive mind map for data science.
I’d like to create a practical guide for a technology-agnostic framework that will help business users, data scientists and technology professionals understand the incredibly complex world of analytics. Below, is a diagrammatic representation of this framework:
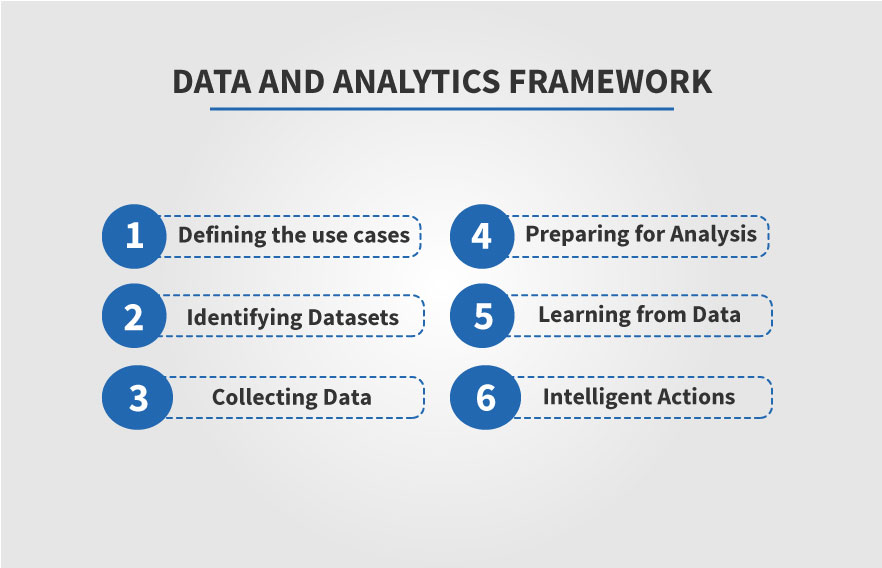
Data and Analytics Framework
As indicated in the figure above, the framework consists of six layers – Use Cases, Data Sets, Data Collection, Data Preparation, Learning and Intelligent Actions. In this blog, we’ll dive in-depth into these layers, understanding the technologies, the principles and the implementation. We will also look at how these layers come together in sectors and functions such as marketing, customer management, fraud management, manufacturing, risk management, personalization, consumer insights, healthcare, and government.
Before we get started, let’s look at the three underlying reasons that drive the adoption of data science:
- Financial: The cost of computing, storage and software have fallen significantly. Open source software is dominating the data science software landscape, whereas cloud services, pioneered by Amazon Web Services, have dramatically reduced the key cost of technology (the initial capex and the ongoing maintenance cost) through economies of scale and automation, and thus made it accessible to startups and large companies alike.
- Technological: There is a convergence of many technologies that are coming together – artificial intelligence, ability to crunch the data, and the generation of huge volumes of digital data. Without the data, the ability to process it and the ability to learn from it, data science would not have taken off.
- Social: In the book Homo Deus, the author Yuval Noah Harari argues that humans, having successfully subjugated the scourges of famine, diseases and war, can now focus attention on “seeking bliss and immortality… upgrade ourselves into gods.” While I don’t know if the dystopian world Harari depicts will come to fruition, AI, Machine Learning, etc. is helping each of us play God with nature in our own ways.
Now that we’ve seen why data science is becoming so relevant today, let’s briefly look at its evolution. As I said, data science is a convergence of three technological trends, so the evolution should look at three areas: Artificial Intelligence (AI), Data Generation and Data Processing. Obviously, books have been written for each area, so I’m not going to go into the evolution in a lot of detail.
Broadly speaking, in the 1990s and 2000s, enterprises big and small have automated their business processes. This resulted in digitization of business processes, generating huge volumes of structured enterprise data, and the emergence of storage and processing technologies.
After this period, internet companies digitized people-to-people interactions. This led to an explosion in the volumes of data, and the emergence of a new class of technologies (such as the Hadoop ecosystem) to manage and process all of this data.
The next step in this evolution is the emergence of IoT. These are a large number (20 billion things by 2020, according to Gartner) of very chatty things that continuously stream huge amounts of data from the edge of networks. The technologies to manage this are only now slowly emerging. There’s also the evolution of GPU-based computing and frameworks like TensorFlow.
Now, with all of the data and computing power available, researchers at leading companies such as Amazon, Baidu, Facebook, Google and Microsoft, as well as those in University AI departments refined old algorithms and invented new (deep convolutional neural networks and recurrent networks) ones. Application of these algorithms led to results that rival and sometimes surpass humans in tasks that were traditionally thought to be beyond the ability of machines (tasks that involve expert human judgment), such as cancer identification, image classification and recognition, language translation, playing games such as Go, driving cars, etc.
In order to understand all of this better, we need a technology-agnostic framework. Let’s briefly look at the layers in our technology-agnostic data science and analytics framework:
- Use Cases: What problems are we trying to solve? What results are we trying to accomplish? How will data science help us (problems/results)? What does the solution look like?
- Datasets: This is the starting point for all data science. What data do we have access to? Are they structured, or unstructured, or in-between? Are they static or flowing? Where do they come from?
- Data Collection: How should we collect data? Where should they be stored (cloud, on premise, hybrid)? What type of storage is best for the data? Should we define the schema upfront?
- Data Preparation: What should we do to make the data ready for analysis? How do we ingest it from various types of sources? What are the different processing techniques to be applied? How do we manage the operation of the data pipeline?
- Learning: What happened in our business? Why did something happen? What is likely to happen? What is the best decision to make given our knowledge about what happened, what’s likely to happen, and the limited resources we have?
- Intelligent Actions: How do we embed the results of analysis into business processes? How do we design user interfaces that enable adoption of this technology in day-to-day decision making? How can we automate the process of making operational, insight-driven decisions?
Engineering infrastructure is a complex, layered framework and to understand it better, we need to peel one layer at a time! Look forward to breaking through the data engineering wall, brick by brick, in the subsequent discussions.
Click here to read part 2 of our blog series titled ‘Decoding the Data Science terrain’!


