


Data is the most crucial ladder for an organization to ramp up its position in today’s competitive market world. Data is everywhere, and the need to collect and record it in a proper format is most important for further analysis and drawing actionable insights to make data-driven business decisions. This is where Data Engineers come into the picture.
According to the big data news portal Datanami, Data Engineers have become valuable resources who can harness the value of data for business objectives. They play a strategic role in a complex landscape, which is essential to the entire organization. In addition, Data Engineers are responsible for data management – to make sure data reaches end-users to generate reports, insights, dashboards, and feeds to other downstream systems.
Usually, an ETL ( Extract, Transform, Load) tool is used to create data pipelines and migrate large volumes of data. But in today’s world, where big data is available in abundance, real-time data analysis is crucial to perform quick evaluation and take necessary action. So, companies are seeking the expertise of data engineers to guide data strategy and pipeline optimization over manually writing ETL code and cleaning data.
This blog will cover important tips to keep in mind when optimizing your ETL tools with use-cases for better understanding.
How to Optimise Your Data Pipeline
Several challenges occur while moving vast volumes of data, but the main goal while optimizing data is to reduce data loss and ETL run downtime. Here’s how you can optimize the data pipeline effectively:
- Parallelize Data Flow: Concurrent or simultaneous data flow can save much time instead of running all the data sequentially. This is possible if the data flow doesn’t depend on one another. For example, there is a requirement to import 15 structured data tables from one source to another. However, the data tables don’t rely on each other, so instead of running all the tables one by one in a sequence, we can run three batches of tables parallelly. As a result, each batch can run five tables simultaneously. This reduces the runtime of the pipeline to 1/3rd of the serial run.

- Apply Data Quality Checks: Data Quality can be jeopardized at any level, so Data Engineers must make an effort to ensure that data quality is high. An example of such checks is using a schema-based test, where each data table can be tested with predefined checks, including column data type and the presence of null/blank data. If the data checks match, the desired output can be produced; else, the data is rejected. Also, to avoid duplicate records, one can introduce indexing in the table.

- Create Generic Pipelines: Multiple groups inside and outside your team often need the same core data to perform their analyses. If a particular pipeline/code is repeated, the same piece of code can be reused. If a new pipeline needs to be built, we can use the existing code if and wherever required. This allows us to reuse pipeline assets to create new pipelines without having to develop them from scratch.
To make a pipeline generic, parameterizing the values instead of hardcoding should be practiced. Parameters are used so that one can run the job easily by simply changing only the values. For example, database connection details can vary across different teams, and connection values can change. In such cases, passing these values in the form of parameters will be useful. The team can now easily use this pipeline by changing the connection parameters and running the job.
- Introduce Email Notification: While monitoring job execution manually, we need to look closely at the log file, which is tedious. The solution to this problem is by sending an email notification that will provide information related to the running status of a job and send an email in case of failure. This results in lesser response time and restarts the work from the failure point in a short duration of time with greater accuracy.
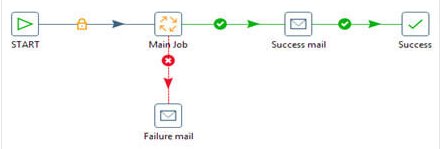
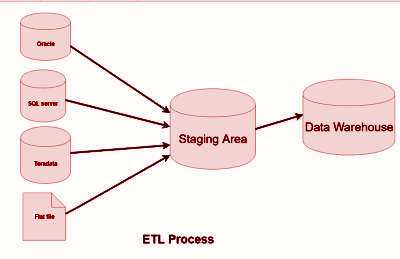
- Implement Documentation: Let’s say a new member has joined the team, and he needs to work on the existing project right away. He wants to understand the work that has been done to date and presents requirements, but the team has not documented the data flow. This makes it challenging for the new member to understand the current workflow and process, resulting in delivery delays. So, a well-documented flow can be beneficial as a guide to understanding the whole workflow. It is preferable to use a flowchart for better understanding. Consider the ETL flow given below. It shows the three basic steps of data flow.
- Extraction of data from source to the staging area,
- Transformation of data in the staging area,
- Loading transformed data to a DataWarehouse
- Use Streaming instead of Batching: Businesses usually accumulate data throughout the day. Therefore regular batch ingestions can miss certain events. This can have serious consequences such as failure of fraud detection/anomalies. Instead, establish continuous streaming ingestion to reduce pipeline latency and equip the business to use recent data.
There’s more to explore
The above tips are generic but can be curated to suit any data optimization challenges. In addition, there are many other ways to optimize your pipeline, including optimizing transformations and data filtering before running through a pipeline to reduce load. Finally, even though thorough data processing is important when building data pipelines, Data Engineers need to ensure that the operations team can use and regulate the pipeline. These data engineering best practices can ensure that your data pipelines are scalable, valid, reusable, and production-ready for consumers of data like data scientists to use for analysis.


