

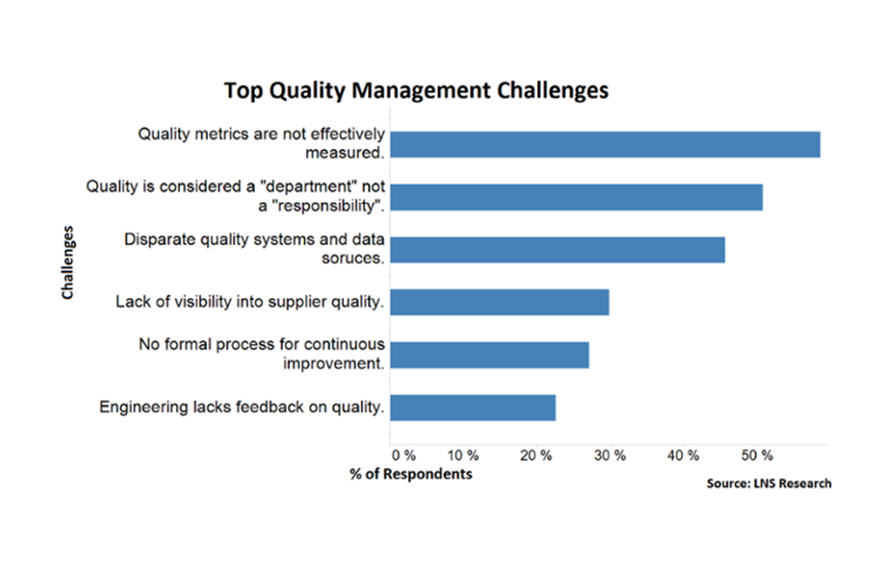
The starting point for any company looking to gain an advantage through analytics is good data. The repercussions of basing business strategy on insights that were derived from inaccurate or poor quality data can be long lasting. In a recent survey conducted by LatentView Analytics, we found that data quality was the number one problem that analytics leaders face, irrespective of the size of the organization (beating even budget cutbacks!).
There are primarily three common challenges that arise with data. The first is when there is missing or incomplete data– for example, missing sales figures for a specific quarter. The second is when complete data streams are unavailable. For example, there is no competitor data from the marketplace. The third is when the data is outdated. For example, data from a three-year old survey. Here are some ways in which companies can get past these common data gaps.
1. Incomplete Data
One of the most common challenges that arises is having missing or incomplete data. This is a case where the data stream for a particular variable exists but is not available for specific periods of time. The following are some of the approaches that LatentView has successfully adopted to overcome this issue.
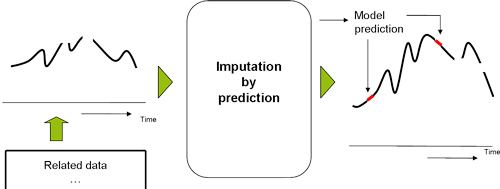
Imputation of variables: In cases where we have missing data for a particular time period, past trends and historical data can be accessed to impute any missing data. However, in cases where historical data is not present, best approximations can be made by running different scenarios. For instance, if the ATL spend is not available for a 3 month period, the spending pattern, for a similar time period in earlier years, is analyzed to determine what should be the imputed values for the missing ATL Spend.
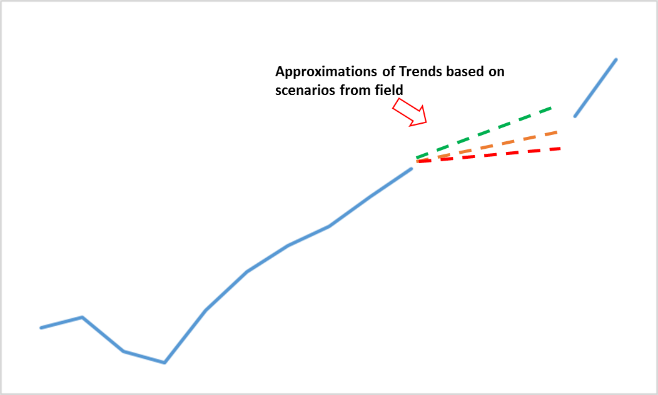
Scenario Based Approximations: Another approach would be to assume different scenarios based on guidance from the field. This could be based on empirical guidance assuming linear growth rates of increasing or decreasing orders of magnitude. For example, an increase in spending can be assumed during the holiday season when forecasting the sales for a product. While, this approach will increase the modeling time, it provides the best approximation when data is completely missing.
Rolling Variables: Rolling averages as the derived independent variable works best when there are minimal sharp spikes or unexplained deviations in the data stream. This approach can been leveraged for forecasting sales, where the driver or independent variable follows a relatively smooth trend.
Adjusting the granularity to account for data gaps: One other approach to account for missing or incomplete data is to adjust the granularity of the analysis. An example of this would be to run the models at a monthly level if we do not have weekly data for specific data streams.
It is crucial to determine which approach will work best based on business and operational contexts. Often, more than one approach is required to resolve the issue effectively.
2. Unavailability of Data Streams:
Unavailability of data streams refers to a scenario where the entire data set for a particular variable is not available. This is a more complex problem as these data streams are critical from a modeling perspective and ensure modeling robustness. For example, there could be no data on competition, or on consumption trends, that is, how the product is being used.
LatentView has developed a robust ‘Innovation Framework’ which leverages unstructured data sets to help address these gaps. Leveraging unconventional and unstructured data sets provides the ability to include aspects and variables in the modeling framework which could not have been included otherwise. Publicly available data sources like social media data and company filings can be embraced to develop new data streams.
Social media data: Social media data (blogs, forums, Facebook, Twitter, LinkedIn, etc.) provides a rich source of information around consumer preferences and attitudes. Natural, unbiased consumer conversations can be leveraged to identify proxies for data streams. A quick review of external conversations relating to a particular topic can determine the top themes and drivers of consumer behavior, which can also be leveraged as proxies. For example, discount related conversations around a competing product could be reasonably used as a proxy for the promotions run by competitors.
Company Filings and Earnings Call Transcripts: Company filings and earnings call transcripts provide a detailed breakdown of Marketing and Sales related spends in addition to providing information on the key risks and challenges faced by the company. They also provide information about the company’s primary focus areas and an industrial overview that will enable monitor competitors activity better.
Other data: Based on the business problem, various other public sources of data can be used. For instance, ingredient data can be mapped with production data to understand price fluctuations, availability, etc. A detailed understanding of the business environment and ecosystem is an often understated factor for improving the accuracy of any model.
3. Outdated Data:
Often the data available with companies is outdated and out of sync with the current business data value. They could impact the efficiency of the model. Here are few measures that can be taken deal with outdated data:
Adjust for changes in demand drivers: Identifying demand drivers and studying their trendlines can help reflect perceptions and adjust the outdated data. For instance, a decline in child obesity rate would imply an increase in health awareness in parents & children.
Cross-reference with other industries: Companies can use syndicated data to cross-reference the existing data with other related industries to draw relevant data streams and insights. For instance, credit card data can be leveraged to identify demographic variations in spending.
Scenario Based Approximations: As discussed earlier, assuming different scenarios based on guidance from the field is one of the methods to overcome the problem of outdated data.
While data quality is an important aspect, there are many techniques to get around while maintaining the efficiency and robustness of the models. It is not just about elevating data as a strategic asset, it’s about having a data quality strategy in place, enabling organizations to make the best out of the data available with them.


