


When it comes to the beauty and personal care industry, the only constant is change – social media is abuzz with trends that change by the minute; what is in style today, is past tense tomorrow, making the market fairly unpredictable and challenging to thrive in for brands. In a forest of self-expression via. social media (Twitter, Instagram, Snapchat etc.), text analytics plays a vital role in decoding consumer sentiment, mine popular opinion, leverage consumer feedback for innovation and spot current trends in real-time.
That being said, trends can originate anywhere across the globe. One of the key challenges, in cases such as these, is the lack of a language expert to decode the natural language of the target population. Is there a way to tackle this language barrier and overcome it? Part two of this blog series (Lingua Franca: An overview of NLP and translation for social media analytics in CPG – Part I),will throw light on how this challenge can dealt with by illustrating a use-case with some examples from Korean social media data.
Use case: The need to mine foreign languages – why is it necessary and how is it relevant?
For a global cosmetic giant, Latentview Analytics wanted to track beauty trends in US region by analyzing text data from various social media platforms. For a time period of one year, Latentview Analytics analyzed trends in beauty to mine insights from consumer COV and sentiment that could be used by the client to identify trends that could become big in the future. Through advanced social media analytics, we discovered that trends such as ‘K-Beauty’, ‘Korean Skincare’ appeared in the observations mined from US data. Brands such as ‘Innisfree’ and ‘Shiseido’ also found mentions in conversations hence it became necessary for the client to track these trends in their places of origin and to see if there is any pattern or trajectory of Korean and Japanese skincare and cosmetic brands slowly finding footing in the market. By identifying trends in foreign language and also tracking the timelines of these trends appearing in the US market, it would be possible to identify future trends originating from these areas. (Shout out to all the BTS fans out there!). The key challenge was to fit the foreign language data into the existing method of analysis and mine trends from it. Handling the volume, cleaning the data, and separating the relevant from the spam terms formed major focus-areas.
The team had already successfully mined English Social Media Text into meaningful trends and automated the process by coupling Deep Learning models to several NLTK methods (discussed in part 1 of this blog). Now, the relevance of the presence of Korean and Japanese trends in these observations had to be explored. Thus, mining text on social media in the native languages of these countries would provide deep-dive insights on what beauty trends and products were being talked about already in US and how are they dependent on the ones in Korea and Japan.
- The Data source: Tweets in Korean and Japanese about beauty and personal care
- The Objective: Mining meaningful beauty trends from those tweets
The language conundrum: lost in translation
Python packages like NLTK have made text mining, Sentiment Analysis, named entity recognition as easy as ABC when it comes to decoding tweets and posts written in English.
However, in social media analytics, posts written in other languages, specifically unknown to one is difficult to handle without a language expert.
Let’s explore the biggest problem associated with the same:
- Tokenization is one of the most primary steps of carrying out Natural Language Processing (NLP) methods. It simply means breaking the text into units (words or sentences) for a given purpose, to attach importance, understand meaning and relevance in the text. NLTK tokenization easily tokenizes into words or sentences based on the need. However, when it comes to Korean or Japanese text, the rules of tokenization or finding out Linguistically Meaningful Units, are unknown. These characters could be treated as tokens, but only to yield the second problem: Spam tokens.
- In this case, the first approach of character tokenization will lead to the creation of millions of tokens from the huge corpora, however not all tokens would be meaningful.
- Other problems include dealing with both Hangul and Hanja for Korean. Clearly it would boil down to lack of linguistic expertise for the assignment.
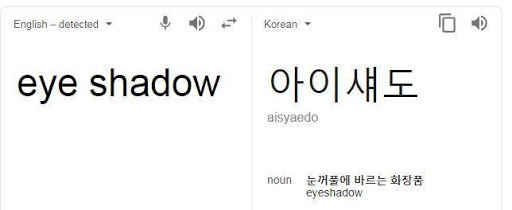
Eyeshadow could be written as eye shadow (two tokens in English), one four-character translation in Korean.
The need for KoNLPY and WHOOSH for language indexing
KoNLPy (pronounced “ko en el PIE”) is a Python package for NLP of the Korean language. Whoosh is a package for language indexing and searching N-Grams.
KoNLPy has powerful NLP methods for POS-tagging with fast and effective performance, in the experimental phase meaningful nouns were extracted.

Image 1: POS tagging (“I love Korea”) using KoNLPy
In spite of using this package, extracting relevant trends from a totally unknown corpus about a very specific industry using methods trained by very generic text did not produce effective results.
For instance trends like ‘cat-eyeshadow’, ‘baked-highlighter’ are too specific to be mined using POS tagging methods by KoNLPy. In this particular case, WHOOSH proved to be more useful in tokenizing, since it created character grams which could be successfully translated, and the spurious words were filtered out.
This approach was implemented, and N-grams were generated by a Whoosh tokenizer, translated and passed to the existing model for spam identification in order to extract trends in English.
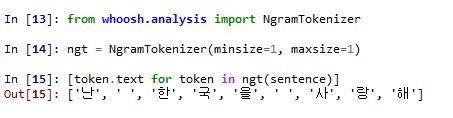
Image 2: Tokenizing (“I love Korea” using a Whoosh analyzer)
However even in this approach, the necessity of translation still remained absolute. The two packages nevertheless are a successful find, for smaller corpora where the time required for translation is not high, and taking the nouns or naming words from the text will not be a waste. It is important to note that a large amount of text was present in two languages and translation of samples was considered using Google Translate add-on for Google Sheets initially. It was followed by usage of APIs.
Translation with APIs (Google and Yandex)
One of the ways to translate large scale text it to use the Google Translate API, the unofficial version of which has got widespread stability issues.

The wrapper classes for Google API are googletrans, goslate, translate. However, all proved to be unstable.
On the other hand, Yandex provided a pretty stable API, and a free API key for one account, the daily limit being 1 million characters and 10 million being the total limit. Using this, a significant sample of the data can be translated, enough to extract useful tokens and mining relevant trends. The wrapper class was Yandex Translate.
Machine translation: Pros and cons
Using Deep Learning for Machine translation is a lucrative and an all-encompassing option, but it does come with its own set of unique challenges – the primary one being labelling. Open Translation Corpora under The Creative Commons Licenses is available, however that may not suit the text for a particular use case.
The options of Machine translation are still not too far beyond reach, however that will be a more long-term engagement. Translating relevant data using APIs, or Google sheets and long-term labelling will definitely allow us to build a huge and relevant dataset required for the purpose. For small texts, using KoNLPy to identify named entities, translating and isolating them seems more viable.
Bottlenecks and coming to ‘terms’
Most NPL methods have its drawbacks – no translation is perfect, and many terms are literally lost in translation. Assuming that there is no language expert involved in this case study, the problem cannot be wholly eliminated. KoNLPy and Whoosh are only steps towards analysis and they will only help make the research a little easier. Without a language expert, sheets full of foreign language can look intimidating. Mining whatever information available is important in such cases, and these approaches can help streamline the process and make it less taxing.
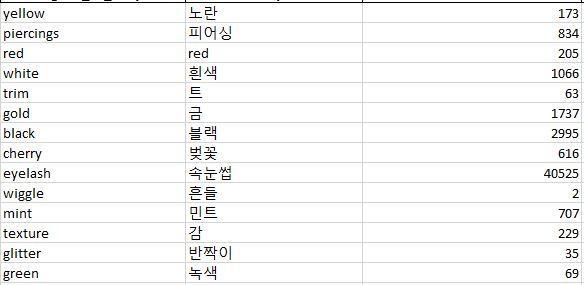
Image 4: A snapshot of sample valid trends
Saying 안녕하세요 (hello) to the future
Working on client requirements calls for quick strategies and immediate resolutions. However, when it comes to mining text, it is important to look at the bigger picture and larger use of these NLP methods. Yandex Translate and KoNLPy have not only helped in mining information at present, but have also demonstrated a way ahead for creating a dataset for a neural network.
Yandex API translations are free for ten million characters, and that means thousands of Bilingual Phrase Translations. These examples can be used to train a Neural Translation Model, and with packages like Keras and Tensorflow, it is not too difficult to delve into Deep Learning anymore. While the translated data may fall short for the purposes of building a global translation model, it will definitely serve a much smaller domain like the beauty and personal care market. Bilingual Phrase Translations could well be the next step and since they are the first steps to a Neural Translation Model, that’s how we could be saying 안녕하세요 (Korean: Anneyonghaseyo, English: Hi!) to the future!
Decoding consumer conversation to predict trends
Natural Language Processing (NLP) is growing in stature and can be applied in a variety of situations that deal with text data. In this time where businesses are flooded with more data, these techniques provide decisive insights which was not practical with manual means. LatentView Analytics, as experts in harnessing unconventional sources of data, is working on cutting edge NLP methods helping global brands understand the pulse of the consumer. For more details, write into: marketing@latentview.com


