


Cancer is one of the fatal diseases of our time, which is becoming increasingly prevalent. World Health Organisation (WHO) says, “Over the next two decades, the number of new cancer cases will rise by about 70%”. With the survival rate has doubled, there have been huge strides in the fight against cancer, yet a general cure remains indefinable.
There is no one-size-fits-all solution. The challenge in treating Cancer is that every cancerous tumour is different, and each one grows and develops uniquely. One tumour can possess billions of cells, each of which can mutate in its way. And because these cancer cells can add new mutations and new genetic variations each time they divide, as the tumour grows and develops, they can become an almost infinite multitude of variations on the genome level.
This makes treating cancer incredibly complex, with oncologists attempting to stop an unpredictable, moving target. The development of Artificial Intelligence has led to significant developments of ideas in translational oncology. Although there is no one-stop solution for caner in Big data yet, researchers are working on various models and testing copious possible theories with the data available to make cancer treatment a less challenging task.
The data mountain:
What we currently have is data and lots of it. One terabyte of biomedical data, which is equivalent to storing more than 300,000 photos or 130,000 books, can be generated from a single cancer patient. This data consists of patient’s all clinical data as well as their routine diagnostic data.
As DNA sequencing cost has plummeted over the past two decades, collection of detailed genetic information on both the patient and the tumour has become far more conventional, rapidly expanding the size of data available to scientists.
The available data can be classified into 3 levels to be analyzed:
- Cellular – Discover genetic biomarkers by finding common features to predict better the mutation of individual tumours and the drug treatments that might be most effective.
- Patient – Based on the patient’s genes and the impact of treatments on patients with similar patterns of disease and genetics, a patient’s medical history and DNA data could be used to help identify the best combination of therapies for them.
- Population – Data from a broader population can be analyzed to arrive at treatment strategies based on different lifestyles, geographies, and cancer types.
Machine Learning to analyse data:
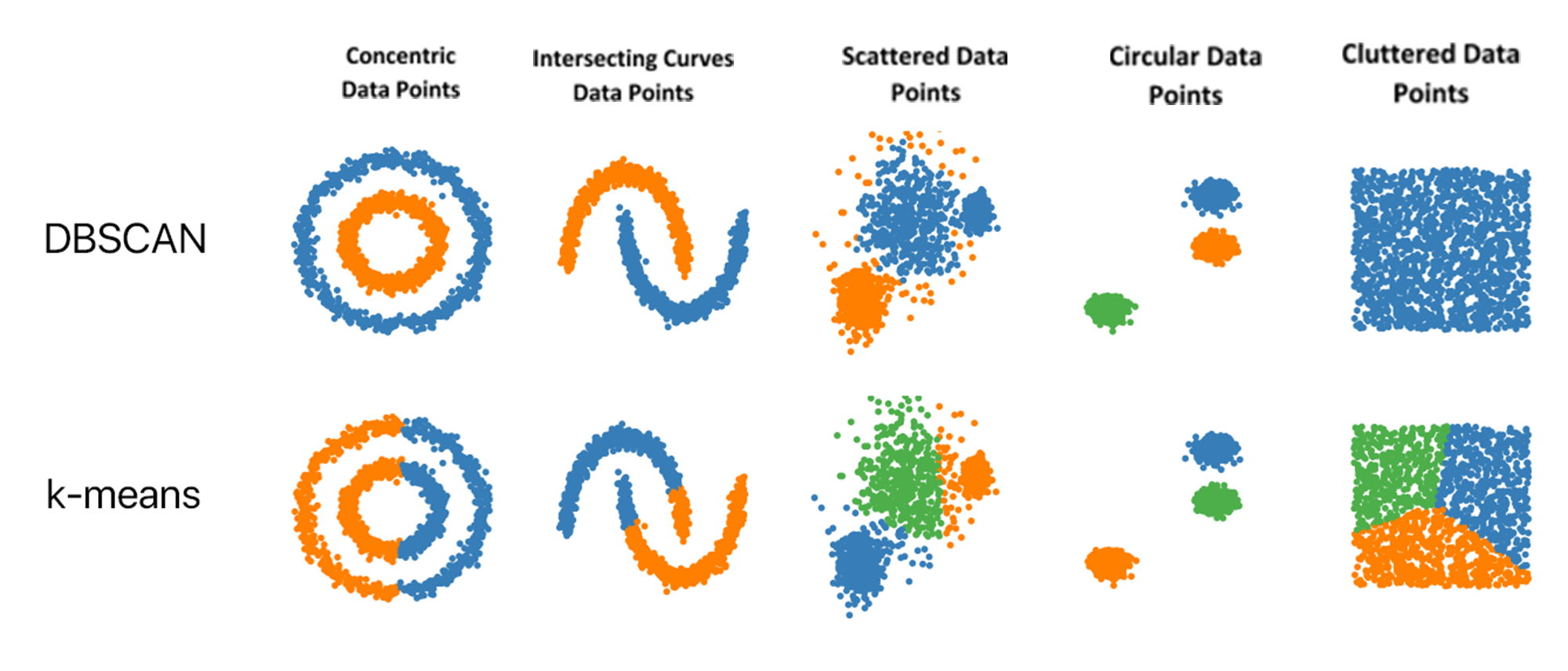
One of the key elements in fighting cancer is the ability to perform high-quality chart abstraction: the process of collecting important information from a patient’s medical record and transcribing that information into discrete fields at scale on hundreds of thousands of patients. This requires technology to improve efficiency and to provide oversight and monitoring. Machine-learning technology can be used to help identify patients and designate cohorts for research. Machine-learning approaches help us efficiently build and populate data models for conducting research. Proper planning, along with validation of the selected analytical approach, will provide greater confidence in the meaning of the results. Two such Machine-learning approaches that can be used for this purpose are SOM for dimensionality reduction of data and DBSCAN for clustering.
For dimensionality reduction, a self-organizing map (SOM) can be used, which is a type of artificial neural network (ANN) that is trained using unsupervised learning to produce a low-dimensional (typically two-dimensional), discretized representation of the training sample(map). They differ from other ANNs as they apply competitive learning as opposed to error-correction learning. In competitive learning, nodes compete for the right to respond to a subset of the input data, which is well suited to find clusters within data. In contrast, error-correction learning is trained with supervised learning to compare the system output with the desired output value, and that error is used to direct the training. Dimensionality reduction is used to reduce the time and storage space required. The removal of multi-collinearity(dimensions) improves the interpretation of the parameters of the machine learning model. It becomes easier to visualize the data when reduced to shallow dimensions (2D or 3D).
Density-based spatial clustering of applications with noise (DBSCAN) is a clustering method that is used to separate clusters of high-density from low-density clusters. Given a set of points, it groups together points that are closely packed and marks outlier points that lie alone in low-density regions. DBSCAN poses some great advantages over other clustering algorithms. It does not require a pre-set number of clusters. It identifies outliers as noises, unlike other algorithms that throw them into a cluster even if the data point is very different.
Difference between DBSCAN and K-means in clustering various shapes of Data points
How can Big data help cancer diagnosis?
SOMs and DBSCAN can be used to create patient cohort clusters based on similarities. The results of the analysis can be used to segment the historical patient data into clusters or subsets, which share common variable values and survivability based on the treatment provided. These clusters, with associated patterns, can be used to train models for an improved patient treatment analysis. The treatment prediction accuracy can be enhanced by using identified patient cohorts as opposed to using raw historical data. Analysis of variable values in each cohort will provide better insights into the treatment of a subgroup. The dataset available can be used to identify patterns associated with the treatment of specific cancer patients. All these methods are data-driven and require input from users or experts.
SOM consolidates patients into cohorts of patients with similar cancer characteristics from which DBSCAN can identify and extract clusters. Patients in each of these clusters will have different kinds of mutations. The separation of patients into clusters will improve overall treatment accuracy.
Providing each patient with a tailor-made treatment based on their cohorts, increasing their survivability is the end goal of the approach.
Challenges in using Big Data against Cancer:
The sheer unpredictability of tumour mutation makes the task of finding an answer in all the available data far harder.
The challenge is not accumulating patient data but the ability to manage and analyse it effectively properly. Just like there is no one panacea for cancer, there is no single tool for analysing the data. Researchers constantly have to catch up. As soon as new tools and techniques are required to process all this information are developed efficiently, more data sources will emerge, and the computational demands will grow ever larger.
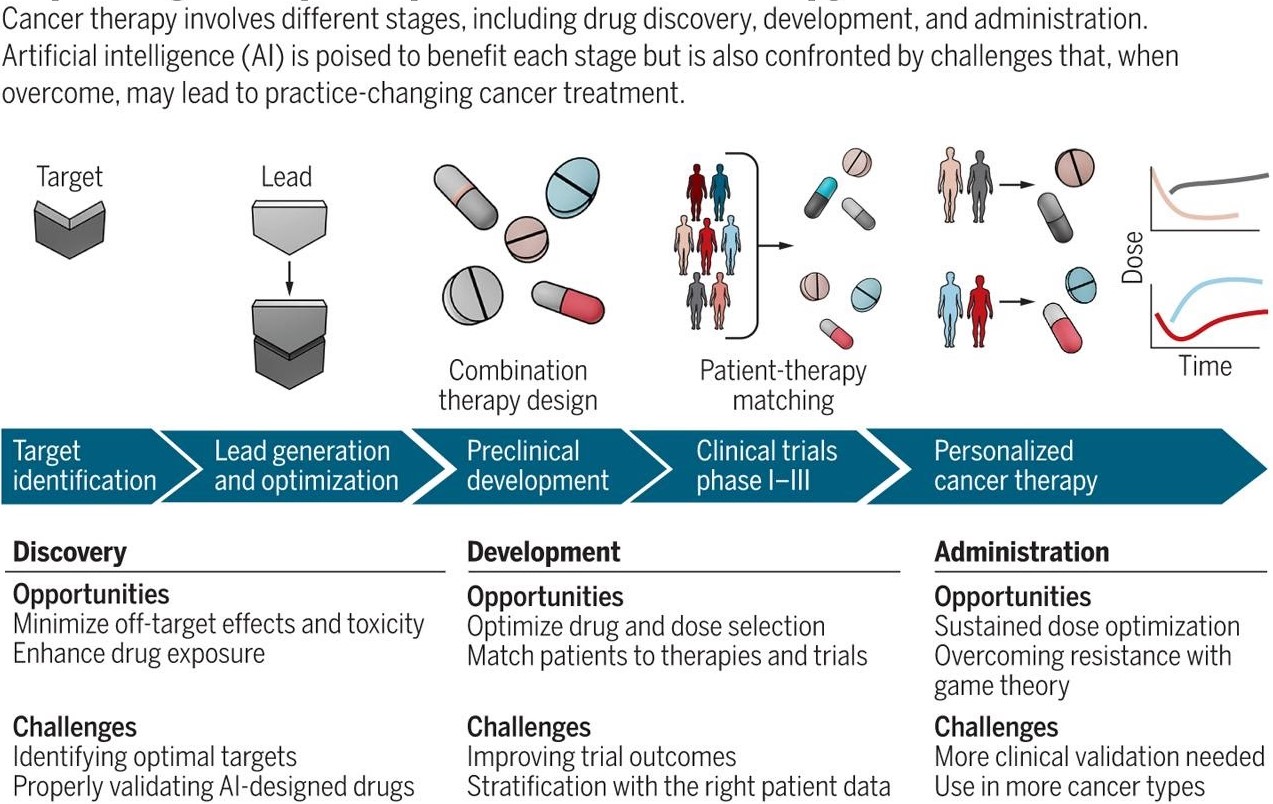
The power of collective wisdom:
Although the cancer drug discovery with Big Data and AI is more of an ideology than a methodology at present, the mountains of information have the potential to help the oncologists deliver tailor-made treatments to patients that can target the tumour better and lower the possible side-effects. The solution lies in greater collaboration i.e., working collectively to use multiple tools, each exploring a specific characteristic of specific cancer.
If the 20th-century challenge in medicine was about the quest for data, the 21st century is about how we work together to better use it.


