


Customers are the most valuable asset to any organization in today’s business world. Therefore, an organization needs to understand customer requirements and behavior patterns to retain them. Customer retention refers to the ability of a business to hold its customers/users over a specified period to boost its business revenue and increase customer loyalty. When a business loses customers at a higher rate than it gains customers, it loses its brand value, resulting in a loss in revenue.
What causes a high churn rate & why should businesses worry about it?
A company faces a high churn rate when,
- Customers are not satisfied with the features/functionalities available in the product
- Increasing bugs/issues in the product
- Competitor’s product is more advanced
- Difference in subscription & pricing
Losing Customers to Competitors
The customers’ requirements could be met by many similar products/platforms. For instance, if the user is shopping for a shoe, multiple e-commerce sites sell shoes with similar features. In this case, one e-commerce website can be considered an alternative/substitute for another. Similarly, one product could replace another with similar functionalities, leading to churn.
To prevent customer churn, some of the measures include:
- Identifying the customers at risk of churn and providing appealing offers/improvements/marketing to them
- Analyzing the churn when it happens and identifying the factors playing a significant role
- Keeping up with the competition and regularly updating products to meet customer requirements & accommodating new features
When a new feature is introduced in a product, it will help retain the customers or churn if the feature is not well received.
How to Predict Customer Churn
We have outlined an approach to determine whether a new feature introduced in a product helps increase or decrease the retention of users, i.e., if they move to a competitor’s product or not post using the new feature, with the help of a churn prediction model.
Data Preparation
- Historical data of the customer’s usage of the company’s product and the competitor’s product is required to study the products’ usage time before and after using the new feature
- Pre and Post period data for each customer based on the first usage of the new feature
- Since different customers might have used the new feature for the first time on different days, the Pre & Post period will be different for each customer depending on their first engagement with the new feature
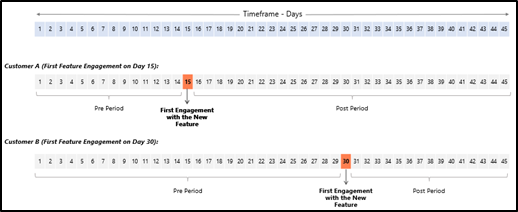
- Feature engineering on the variables before feeding the data to the model for achieving better model performance
- Preparing model input variables including Customer Type, Group, Product Usage Time, Feature Usage time
Identifying Churn Customers
- To determine whether a user churned, one should evaluate the churn criteria
- In this case, determining whether customers churned post new feature engagement is key; Churn can be defined as the users who used the company’s product before the new feature engagement and switched to competitor’s product after engagement.
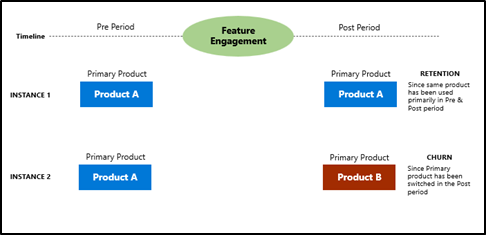
- ‘Primary product’ can be determined using variables like product usage time and engagement time.
Churn Prediction Model
Problem formulation
The main objective is to determine whether customers churn after feature engagement. Hence, it is a binary classification problem, and we need to build the model accordingly.
Exploratory Data Analysis (EDA)
First, we need to perform Exploratory Data Analysis (EDA) on our data to understand the variables better and determine the relationships with the target variable – whether the customers will churn. We will be using the information gained from here in Feature Engineering to get better performance.
Feature Engineering
- Check if the dataset is balanced (i.e., an equal split of churn and not churn labels) for the model to predict with good accuracy
- Decode the categorical variables, if any (Example: Customer Type, Group), to integers
- Some of the numerical variables, including Product usage time and Feature usage time, can be turned into categories by creating buckets based on the existing values
- Some variables may not have a direct relationship with the target variable, and hence creating a new variable from the existing ones that do not have a direct relationship or combination of such variables would help in better accuracy
Model
Once the above steps are completed, different classification models can determine whether the new feature increased or decreased customer retention. Then, the model with better performance can be selected to derive the final result.
- Input for the Model
- Using the historical Pre and Post data, the user can be tagged as churned or not based on the product usage time
- Data needs to be transformed into one record per user with details on time spent on our product, competitor’s product, time spent on the new feature, customer type, group, and so on. This will be used as input for the model
- Logistic Regression
Build a logistic regression model and tune the hyperparameters to get the best fit model. Based on the model result, we can determine the probability of customer churn or retention for a different set of significant predictor variables
- Decision Tree
A decision tree model creates a yes or no branch continuously until all the data points are used or based on the limit we set and will help us identify the group the customers belong to (either churn or not churn). Based on the branches, we can determine the conditions to identify churn
- Performance Metrics
- Based on the precision, recall, and accuracy, we can select the model with better performance for the final result
- Output
- Using the model output, we can determine the Churn/Retention possibility post engagement with the new feature in our product. Based on that, we can conclude whether the new feature has helped in retaining customers or not
Conclusion
The churn model can help us determine whether the users churned or not post the new feature. Furthermore, we can use the model to regularly observe and evaluate the customers. We can implement similar methodology across different industries to determine whether the customers churn and the factors that played a significant role to help the business bring down the churn.


