


Adopting DevOps principles in Machine learning
I recently attended the AWS re: Invent summit 2019 at Las Vegas along with my client and was mesmerized by the sheer scale of the services that AWS is offering at their cloud platform. Our Client who is the leading German media company presented their ML journey on cloud (Official video link: https://www.youtube.com/watch?v=2RSCsgqyKmU). Additionally, there were a lot of exciting announcements around 5G wireless, new hardware capabilities, and cloud security features, but a common trend I observed across all the AI and ML presenters was the emergence of ML-Ops. AWS has always followed a “direct from customer” feedback approach while deciding the next line of services they should launch and a common concern which they addressed this year for data science and machine learning practitioners was operationalizing Machine Learning algorithms. If you or your team build ML-Ops models, you might agree that in the Machine learning world, Development is easy, but operations are hard.
Although machine learning has now been around for more than 5 decades, much of the progress of machine learning application has been observed around the development tools like the IDEs, packages/libraries and statistical techniques with very little focus on the deployment and maintenance of the algorithms. The ability to deploy new models remains a challenge as the pipeline to deploy new models can take weeks or months with many models never making it to production. Since the last decade saw a widespread adaptation of data science and machine learning in day to day business activities in several organizations, building and deploying machine learning models is becoming more and more frequent and there is a need to have a sophisticated platform to handle these frequent deployments. One solution is to adopt DevOps principles to Machine Learning ( MLOps ) and application of AWS Sagemaker does an excellent job in bringing DevOps concepts to Machine learning. It is bridging the differences in the way a Data Scientist and Data Engineer operate within an organization by giving a data scientist more time to work on repetitive tasks like model improvement and business enhancements rather than setting up pipelines, testing and periodic maintenance of the models.
This year at Re: invent, AWS Sagemaker was announced as a “fully managed end-to-end ML-Ops service that enables data scientists, developers, and machine learning experts to quickly build, train, and host machine learning models at scale.”
So, what does it mean for a Data Scientist?
It translates to quicker prototyping, deployment and easy monitoring of the ML-Ops on the scale. Let us look at a typical lifecycle of a Machine learning model, it consists of the following stages:
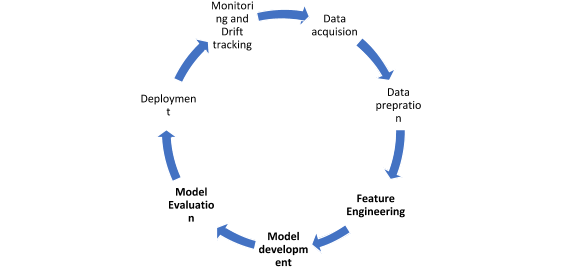
In a traditional setup, a Data scientist iterates through each of these steps in a cyclic way to implement a new model into production. This technique holds good if the deployment cycle is once a month or quarter, but in today’s world, where organizations are moving towards working in DevOps mode, it looks primitive to wait for months for every deployment. If you look at this from a data scientist’s perspective, the core steps (Feature engineering, model development, and evaluation) only make up to 5-10% of the entire effort and this is where all the machine learning magic lies. If you are aiming for production-grade scalability, these core operations should be where a data scientist should spend maximum effort.
Additionally, if we need this model to be retrained daily and make predictions in real-time, doing so in this cyclic approach might not be feasible.
So how does the application of AWS sagemaker services, help in productionalizing the ML-Opson the scale with minimum effort?
This can be done by splitting up the above-mentioned cyclic process and orchestrating it as a combination of distinct pipelines and model development step as shown below:

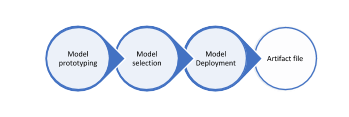
Using this approach, we decouple the machine learning algorithm development process from orchestration and deployment processes. A data scientist writes the Machine learning code. That ML code is put in a AWS Sagemaker training job, which can be run based on the desired frequency independently as and when new data arrives. And a separate job (inference pipeline) runs predictions independently by using the model artifacts created by the training job.
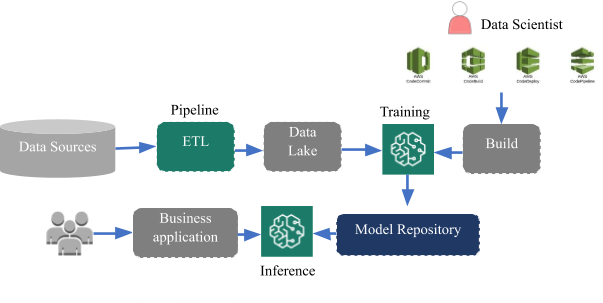
When you introduce the CI-CD pipelines and continuous deployment frameworks in the mix using services like Glue, Code Commit, CloudFormation templates, we end up replicating DevOps concepts for ML-Ops. Such a loosely coupled architecture helps us achieve continuous development and deployment of ML-Ops at scale without any business downtime and maintenance schedules. It provides us the flexibility to build a new model, update or finetune an existing model and deploy the changes in the production within hours. Additionally, we can also leverage the newly launched features of AWS SageMaker studio-like experiments, Autopilot, Debugger and Model Monitor to accelerate the process.
As per the industry trends and widespread adoption of cloud technologies, LatentView has setup Data Engineering as a separate practice, where we help our clients with consulting, architecting and implementing these types of cloud solutions. The unique proposition of our solution is the Business-focused approach towards data engineering to align analytics and technology solution resonates with the overall business objectives of the client.


