


During Microsoft Build ’23, Satya Nadella introduced Fabric as the biggest data product from Microsoft, only after the SQL server. And since then, it has been the talk of the data analytics world. To further spur our interest, we were given a free trial access to the Fabric services by Microsoft, to play with the offerings of the SaaS. Learning and understanding the capabilities of Fabric was an exciting experience for our team. Our experience resonated with what was shared in the keynote address, during the build – Fabric is, in fact, a unified experience for all data professionals.
Microsoft Fabric is a comprehensive cloud solution that combines data movement, engineering, integration, science, real-time analytics, and PowerBI reporting in a user-friendly, all-in-one SaaS package. It is powered by a unified analytics solution that offers organizations strong data security, governance, and compliance.
Going forward, an organization need not manually combine its data engineering services, and instead use a single platform to connect, extract, transform and load. This unified platform puts together all individual analytics services under one umbrella, preparing the data for data science and business Intelligence reporting.
Microsoft Fabric Overview
The image below of Fabric sums up what the SaaS can offer.

OneLake is an open-format storage layer. Data is stored in Delta Parquet format, which is open source and is being used by multiple data offerings like Databricks. Next is the compute layer, which is serverless with Fabric and completely decoupled with storage. Such a compute layer will ensure efficient usage and maximum cost savings.
The seven main components of Fabric:
1. Data Factory is a matured version of the Azure Data Factory the data engineer uses today; it is integrated with the dataflow gen2. It comes with 170+ connectors and 300+ ready-to-use templates for transformations. One of the most common transformations we do with ADF today is ‘Copy’ – Fabric has introduced ‘FastCopy’ to move data between datastores.
2. Synapse Data Engineering is the notebook component of Fabric. The notebooks are designed to run on the Spark framework, which is completely customizable with delta optimizations like V-order.
3. Synapse Data Science provides a rich set of built-in ML tools in addition to accessing low code data preparation tools in Data Wrangler. SynapseML is a newly introduced simple and distributed machine learning library for Spark.
4. Synapse Data Warehouse is built to support open data format without compromising governance and security.
5. Real-time Analytics integrates seamlessly with all other Fabric components, allowing users to get insights from real-time datasets without much work.
6. Power BI is the crucial component of Fabric. Or rather, Fabric has been introduced as an advanced offering of Power BI. The visualization tool is getting enhanced with new features like Copilot and Autocreate.
7. Data Activator monitors data patterns and triggers notifications based on the criteria set – all this with no code.
Data Engineering Intensive Implementation in Fabric
We had a telemetry use case that we wanted to implement in Fabric. Our goal was to ingest both batch and real-time telemetry data from the source, process it through the lake house and KQL Database, and then visualize it using Power BI.
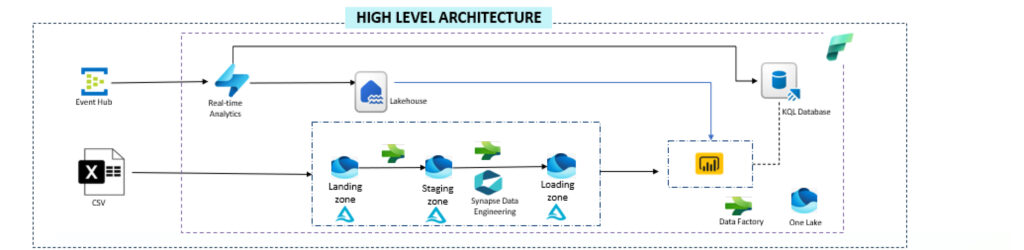
We collected data related to battery health and capacity, and decided to stream some fields in real time, while capturing others in batches. To implement this project, we assumed some fields from the dataset would be streamed in real-time, and a few others will be captured in batch. We created a custom framework that had a configuration table. This table held the target table name to be loaded and the mode of load (either incremental or truncate and load). A corresponding notebook was called for processing depending on the table name passed. The target table was always a lake house table, and a stored procedure was called to load the target table in question.
We loaded a CSV file as a dataset in ADLS gen2 and created a shortcut in OneLake to source the batch dataset. For the real-time data, we used Azure Event Hubs to generate data and used Event Stream to consume it. We analyzed the real-time data using the KQL database and Power BI and loaded the data after transformations in the lake house as well. We used a copy activity to move the data from the lakehouse to a data warehouse for reporting purposes. We created a detailed report in PowerBI using the Battery health data to derive some insights.
Learnings from the Implementation
Fabric is a unified platform for data analytics solutions. Microsoft has developed this product to make data engineers’ lives easy.
We created a Databricks notebook to access the OneLake dataset and process it. The integration was possible and seemed easier than the ADLS integration. This gives us an option for integrating the Databricks with Fabric.
A data factory, for example, does not need any additional linked services or sink objects to be defined; it is easier to integrate with any source. Additionally, you don’t have to publish it every time you make a change; it is automatically saved. You need not use the Azure key vault as the integration is directly with OneLake now. The job monitoring is detailed in Fabric, and you can now monitor even the cross workspaces.
Data Engineering Notebooks allow high-level collaboration. Multiple team members can work on a single notebook at the same time. The interface is simple to use. The underlying spark framework is customizable, even though it comes with a default robust performance. The facility to call a notebook inside a notebook is very convenient to modularize the codes.
Real-time analytics is quite mature in Fabric, allowing instant explorations and access to the incoming data through KQL databases. Spark structured streaming is not needed in the case of this component, which is a big change from the Azure service offering. Default partitioning and indexing help ensure high performance of the data.
What Makes Fabric a Crowd-puller
Data Exploration
Organizations have transitioned from ETL to ELT as cloud adoption continues to grow. Almost 90% of organizations have moved their data to the cloud for later analysis. However, they often face difficulties in understanding what data is present where, leading to what is now referred to as a data swamp. OneLake can help such organizations by providing a better understanding of their data, and our business professionals can provide more details to enhance the datasets for quicker insights. OneLake shortcuts can be utilized to access and analyze data in various stores using the Power BI Direct Lake mode.
Data Integration
With the right set of access, data integration from various sources can be supported and easily merged with analyzing the sources from a single UI. In multiple implementations, the user loses trust in the dataset because they are unsure if the values shown are right. This is mainly due to a lack of traceability- Fabric can show the data lineage that will allay such inhibitions in the business user’s minds.
A developer’s life is difficult because of the integration overheads in large implementations. In Fabric, with seamless connectivity across various services and completely managed offerings, developers’ efforts are reduced by 20-30% per our experience.
Cost and AI integration
The separation of compute and storage cost calculation is a significant advantage. OneLake already has optimized storage as it is an open format and can be accessed by anyone. Compute pools will be reused based on the execution timeline. It is up to the teams to plan the job executions in a way that the same pool is used by Batch jobs when it is used for PowerBI reports in the morning.
AI integration is being implemented in every layer of the Fabric. The co-pilot will be present in each component of the Fabric, and job processing will be optimized based on previous runs. This is a significant point of differentiation.
Fabric Adoption
Microsoft has been clear in its plan for existing customers. They have always valued them and have a plan for their Fabric movement. ADF mounting is a service that is supported for existing ADF users. Synapse migration pipelines will be available, but it is not defined yet. None of the existing components that Fabric has enhanced will be retired anytime soon. Interestingly, many Amazon S3-specific OneLake capabilities are introduced as part of storage accesses, which will imply a soon-to-be surge in cross-platform access.
The Way Ahead
Even though Fabric is still in the early stages, it holds a huge potential when used correctly. It can serve multiple use cases across various industries. OneLake is a big game changer from a data governance and data cataloging perspective as well. Every underlying database or data warehouse in an open format will encourage people across various cloud platforms to access and share data with users in Azure. One point getting lost in big changes is the integration with MS Teams and office apps- this will be helpful for non-technical teams who need insights. A few more offerings planned as part of Fabric look promising. Semantic link, Data Mirroring, Dynamic lineage, Spark Autotune, Copilot integration in Data factory and notebooks, Git Integration, REST APIs for warehouse, and Workspace enhancements – are a few that pique our interests as Data Engineers.


